Image Source: FreeImages
Es posible que ya haya oído hablar del aprendizaje automático y de otras tecnologías relacionadas con la Inteligencia Artificial (IA). Pues bien, este artículo trata de aumentar la eficacia de sus análisis con técnicas de aprendizaje automático. Veamos cómo puede utilizar el aprendizaje automático en su beneficio. Supongamos que usted es una empresa que necesita comprender el coste y el impacto de varios tipos de inversiones realizadas por sus clientes y socios y elaborar un análisis adecuado teniendo en cuenta las diversas contingencias. Si quiere ser más eficaz en sus actividades de marketing, necesita adoptar nuevas y mejores estrategias de marketing que incluyan el Machine Learning . Puede leer más sobre esto en profundidad en nuestro artículo sobre Cómo aumentar la eficacia de su análisis utilizando técnicas de aprendizaje automático . Veamos cómo puede utilizar las técnicas de Machine Learning para aumentar la eficacia de sus análisis.
¿Qué es el aprendizaje automático?
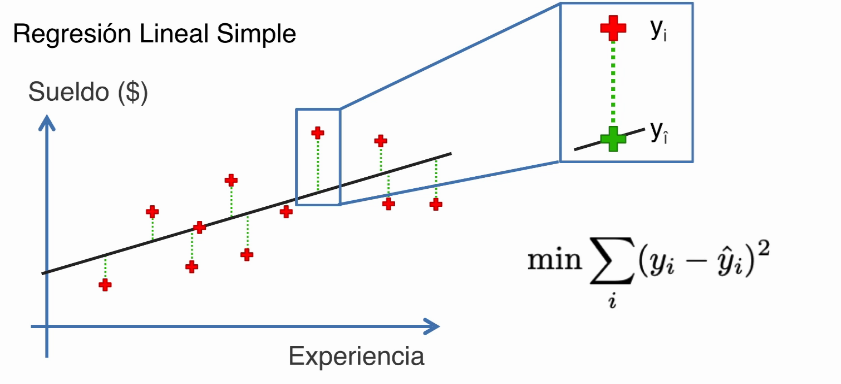
El aprendizaje automático es una rama de la algoritmia que permite a los programas aprender a través de la experiencia y luego aplicar ese conocimiento a nuevos problemas. En este caso, el algoritmo de aprendizaje automático se entrena con datos de muestra para aprender de ellos sin necesidad de escribir código. Esta técnica da lugar a programas que son mucho más fáciles de mantener, mantienen un solo lugar para el almacenamiento de datos y son lo suficientemente generales como para manejar una amplia variedad de problemas.
Cómo aumentar el rendimiento de sus análisis utilizando técnicas de aprendizaje automático
El aprendizaje automático es una técnica que permite a los programas aprender a través de la experiencia y luego aplicar ese conocimiento a nuevos problemas. Esta técnica da lugar a programas que son mucho más fáciles de mantener, mantienen un solo lugar para el almacenamiento de datos y son lo suficientemente generales como para manejar una amplia variedad de problemas. Para medir el rendimiento de sus análisis, utilice una herramienta de supervisión del rendimiento como Metrics Monitor o Streamline para recopilar datos que permitan analizar e informar sobre el estado de sus datos. A continuación, utilice los datos para mejorar sus algoritmos.
Las ventajas de la IA
El aprendizaje automático tiene el potencial de mejorar la eficiencia y el impacto de muchas actividades diferentes. Por ejemplo, puede mejorar el rendimiento del análisis de varios tipos de inversiones realizadas por sus clientes y socios. También puede mejorar su capacidad para comprender y predecir la demanda de los clientes y responder adecuadamente a ella. El aprendizaje automático también puede mejorar su capacidad para crear ofertas y campañas a medida basadas en las necesidades y el comportamiento de sus clientes. Por ejemplo, puede crear una campaña que destaque las ventajas de la IA y luego ayudar a sus clientes a entender el impacto de su elección de ofertas asistidas por la IA. O puede crear una campaña que destaque las ventajas de la IA y luego muestre cómo las herramientas asistidas por la IA pueden utilizarse para reducir las frustraciones de los clientes.
Lo que los algoritmos de aprendizaje automático pueden hacer por sus análisis
Hay una serie de algoritmos de aprendizaje automático que puede utilizar en sus análisis. A continuación hemos enumerado algunos de los más comunes. RNN – El entrenamiento de redes neuronales regulares es el enfoque más común en el aprendizaje automático. Esta técnica utiliza neuronas regulares y una representación interna para producir patrones a gran escala. Se entrena con un gran número de ejemplos para aprender. El número de tareas que puede manejar es limitado. Aprendizaje profundo – El aprendizaje profundo es el enfoque más antiguo del aprendizaje automático. Se basa en redes neuronales descentralizadas y se utiliza para realizar tareas como el reconocimiento de imágenes y el reconocimiento del habla. SVM – El modelo de árbol de decisión estándar utilizado en el aprendizaje automático. También se conoce como «hembra pegajosa». Se basa en atractores en forma de Y y representa las tareas como puntos y luego como incertidumbres. Otras herramientas que puedes utilizar para entrenar tu modelo de IA son los algoritmos tradicionales, como RNN o SVM. Si quieres utilizar otro enfoque, también puedes utilizar redes neuronales para entrenar tu modelo de IA. Cuando se utilizan redes neuronales, cada capa es una representación independiente de los datos de entrada. Este enfoque le permite entrenar sus modelos de IA con un gran número de ejemplos para aumentar su precisión.
¿Qué datos se necesitan para apoyar un algoritmo de aprendizaje automático en una aplicación?
Puede utilizar cualquier conjunto de datos que admita el aprendizaje automático para crear un modelo de aprendizaje automático. Los siguientes son algunos ejemplos de conjuntos de datos que puede utilizar en sus campañas de aprendizaje automático: – Datos de compra del cliente. Esto incluye el código de pedido, el precio y la cantidad comprada. – Datos del comportamiento del cliente. Esto incluye su comportamiento de compra, incluyendo si compraron el producto al por mayor, o si compraron el producto en una sola pieza. – Otros datos. Incluye datos de asesoramiento, datos de campaña y datos de marketing.
Conclusión
Se espera que el aprendizaje automático desempeñe un papel importante en las tecnologías de aprendizaje automático e IA en un futuro próximo. Actualmente se utiliza para entrenar redes neuronales en grandes cantidades de datos para aprender de ellos. A continuación, hablaremos de cómo puede utilizar el aprendizaje automático en su beneficio para aumentar el rendimiento de sus análisis.
Cómo aumentar el rendimiento de sus análisis con técnicas de aprendizaje automático
– Coloque sus datos en un lugar al que pueda acceder fácilmente. De este modo, tendrá un acceso fácil y constante a los datos. – Asegúrese de que los datos están ordenados según alguna regla común. Esto le permite crear datos limpios. – Utilice funciones para crear marcos de datos. Esto le permite mostrar los datos en tablas o gráficos. – Utilice gráficos para mostrar la información. Esto puede ser una muestra visual o métrica. – Configure una campaña de Hora de Aventuras. Los datos seguirán al héroe a través de su viaje y se utilizarán como un marco de datos para representar su progreso. – Concluir las campañas con resultados positivos. Los marcos de datos son una gran manera de compartir los resultados con la comunidad.
Los beneficios de la IA
El aprendizaje automático puede mejorar la eficiencia y el impacto de muchas actividades diferentes. Por ejemplo, puede mejorar la eficiencia y el impacto del análisis de varios tipos de inversiones realizadas por sus clientes y socios. También puede mejorar su capacidad para comprender y predecir la demanda de los clientes y responder adecuadamente a ella. El aprendizaje automático también puede utilizarse para crear ofertas y campañas a medida basadas en las necesidades y el comportamiento de sus clientes. Por ejemplo, puede crear una campaña que destaque las ventajas de la IA y, a continuación, muestre cómo pueden utilizarse las herramientas asistidas por la IA para reducir las frustraciones de los clientes.